AomiBench: Benchmarking Frontier Models on Onchain Execution
aombench_v1_data ├── figures ├── latest.json ├── MANIFEST.md ├── README.md ├── specs └── summaries
A wallet-aware harness for agents executing on blockchains, and how frontier models perform when run through it on real transactions, simulations, and chain-state evidence.
A bad commit can be reverted. A bad transaction usually cannot. That asymmetry is why evaluating an onchain agent is a different problem from evaluating a chatbot or a coding agent. Chain state is contingent, encrypted, and irreversible: a model can produce a fluent plan and still emit the wrong calldata, recipient, or chain id. A transcript that "looks right" tells you little about whether an agent is sound behind a wallet, and it only has one shot to write to a constantly changing, consensused state. What matters is what the agent does to chain state. Aomi is a harness built for exactly that; AomiBench is the evaluation on top of it, where the score is tied to a deterministic verifier reading the chain, the wallet, and the tools.
Across 50 onchain tasks and 7 frontier models (700 runs, 694 scorable), models passed 90.6% of runs. The top five clustered tightly at 94.8–99.0% task success rate, while the two smallest models fell to ~74–77%. v0.1 is, in effect, near-saturated for frontier models — 28 of 50 tasks were solved by every model on both passes — and that saturation is itself the signal that v0.2 needs harder, multi-step tasks.
The remainder of this post is structured as follows. First, we describe the Aomi harness — the agent loop, the two-state model, and the byte-level tool layer. Then we describe how AomiBench is built and verified, and benchmark the models on the 50 tasks. Finally, we discuss the harness mechanisms — skills, guards, injected tools — and what the runs revealed about model behavior.

Figure 1 — Task success rate per model. Headline result shown up front: JSON-only success rate, scaffold held fixed across models, 2 passes (no confidence intervals at this pass count). The dashed line marks the 90.6% overall rate; crediting nine correct safety pauses (Section 4.4) would raise it to 91.9%.
1. Why onchain agents need execution-based evaluation
Most model evaluations stop at answer quality. For agents that touch stateful, financially sensitive systems, that is not enough.
1.1 The lesson from execution benchmarks
The closest analogues are not knowledge benchmarks like MMLU; they are execution benchmarks. SWE-bench grades whether a patch resolves the issue under tests. Terminal-Bench checks the final container state rather than whether the model used a preferred sequence of commands. WebArena moved deliberately away from brittle string-matching and LLM-as-judge toward backend-state verification and deterministic scoring. The shared lesson: where a deterministic checker is feasible, that checker — not a model reading a transcript — should be the headline metric.
1.2 The chain is the source of truth
Onchain execution is unusually well suited to this discipline, because the chain itself is the source of truth. A swap either leaves the wallet in the expected postcondition or it does not. An approval either preceded a transfer or it did not. A required event either appears in the logs or it does not. In a decentralized system, there is only one chance to commit a change. So instead of asking whether an answer looks correct, AomiBench evaluates whether the run left evidence that the agent:
- digested the user's intent;
- internalized the correct context around chain state and wallet conditions;
- called and simulated the exact operations with precise parameters;
- course-corrected after simulation;
- committed well-formed transactions to the user's wallet;
- reflected on callback data once the task completed.
Everything below is organized around producing and checking that evidence.
2. Inside the Aomi harness
If you have used a coding agent, the shape of Aomi is familiar. This section covers what the harness is; the mechanisms that make it trustworthy (skills, guards) come later, in the discussion.
2.1 The same agent loop, a harder world
A coding agent runs a loop over a machine. The state is the codebase and OS; the actions are reads (cat, grep, ls) and writes (edit a file, run the build); the judge is not the model's explanation but the world's end-state — do the tests pass, does the program run. Aomi runs the same loop; only the world changes.

Figure 2 — The same loop, five divergences. The skeleton is identical — a typed action over a mutable world, judged by the world's end-state — but the Aomi world differs at five points: a typed/gated action space, simulation as the only rehearsal, no unilateral write authority, irreversibility, and a shared/adversarial world.
Table 1 — Coding agent vs Aomi agent, axis by axis.
| Coding agent | Aomi agent | |
|---|---|---|
| State / world | codebase + OS: files, processes, env | chain at a pinned fork block + wallet: balances, storage, positions |
| Read | cat, grep, ls, read file | get_time_and_onchain_context, get_account_info, get_contract, encode_and_call |
| Propose | edit file (open-ended) | stage_tx (from a typed, namespaced tool catalog) |
| Verify-before | run tests / build (cheap, repeatable) | simulate_batch (dry-run against the fork) |
| Commit | write to disk — agent has authority | commit_txs → wallet request → wallet signs — agent does not |
| Judge | tests pass? OS output correct? | balance Δ correct? event emitted? final state right? |
The five divergences are each a reason an onchain benchmark is strictly harder than a coding-agent one: (1) the action space is typed and gated, not a free-form shell; (2) simulate_batch against the fork is the only safe rehearsal; (3) commit_txs only requests — a wallet signs, so the agent can "open a PR" but not "merge to main"; (4) an onchain commit is final and costs real value; (5) the chain is shared and adversarial, and only the pinned fork restores replayability.
2.2 Two states, two ground truths
The harness reads two distinct kinds of state, and keeping them separate gives a second verification axis a coding benchmark does not have.
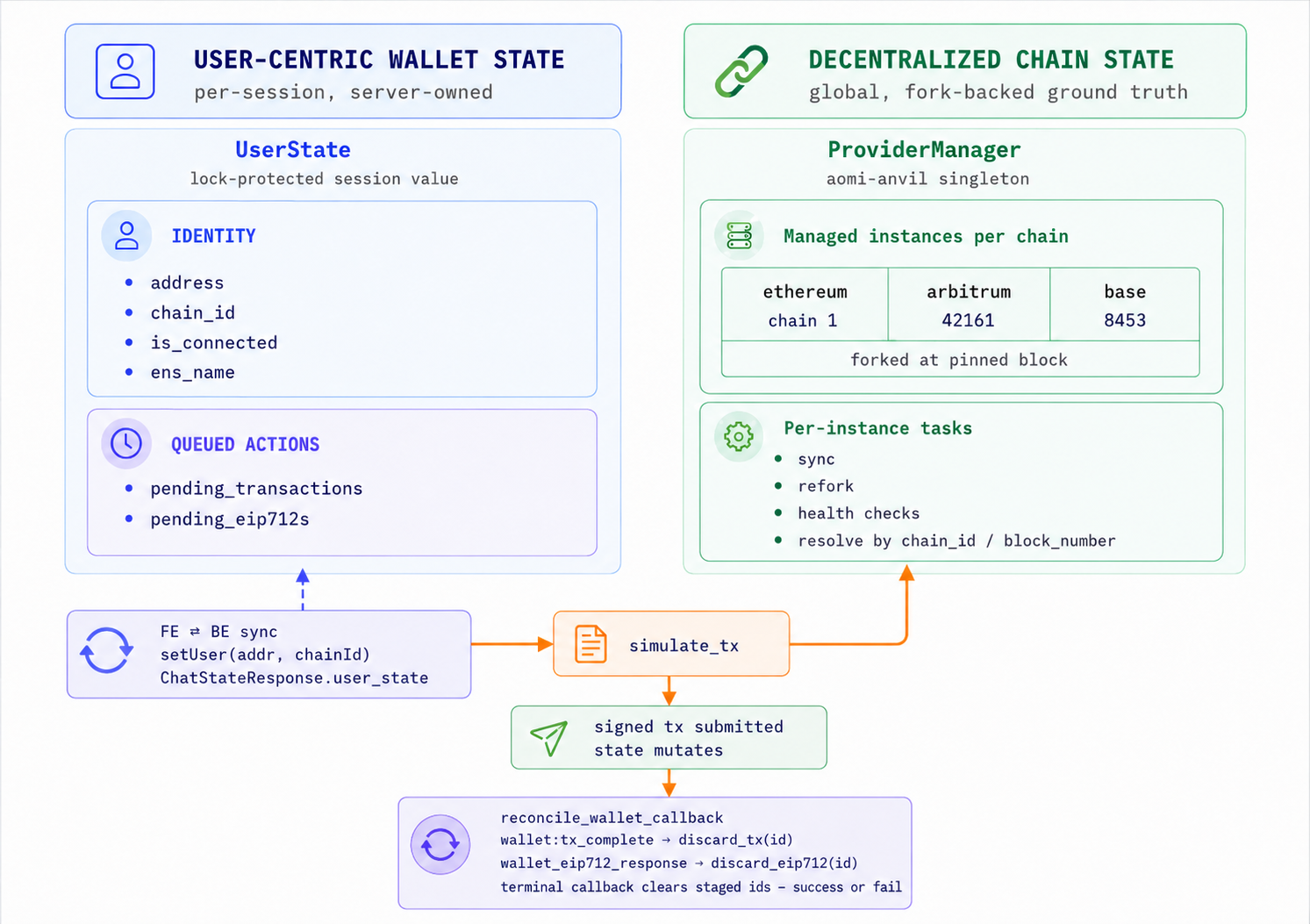
Figure 3 — Wallet state vs chain state. Wallet state is per-session and server-owned: identity plus the agent's pending (unsigned) transactions and EIP-712 requests — reversible, and proof the agent formed the right intent. Chain state is the fork-backed global ground truth: balances, storage, nonces, logs — final, and only a signed transaction mutates it. The agent stages into wallet state; commit_txs requests a signature; a signed tx mutates chain state; a wallet:tx_complete callback reconciles and clears the pending ids.
Table 2 — The two states on every axis.
| Axis | Wallet state (UserState) | Chain state (anvil forks) |
|---|---|---|
| Scope | per-session, per-user | global, shared |
| Owner | backend session (lock-protected) | ProviderManager singleton |
| Holds | identity + pending (unsigned) actions | balances, storage, nonces, logs |
| Authority | agent stages here, wallet signs | only a signed tx mutates it |
| Lifecycle | cleared on terminal callback | sync (reset) + refork (respawn) |
| Reversible? | yes — discard pending | no — committed state is final |
| Eval role | tool / wallet / EIP-712 / pending assertions | balance-Δ / event-log assertions (ground truth) |
The benchmark reads both: wallet state proves the agent formed the right intent (correct tool, recipient/amount in the pending tx, correct EIP-712 payload); chain state proves the outcome actually landed. A model can get one right and the other wrong — two states, two independent ground truths.
2.3 The model never sees a byte
The read/write loop is possible only because of a layer of engineering the model never touches. This is what distinguishes Aomi from exposing a raw RPC endpoint to a model, and it is what makes the benchmark fair: the model is judged on intent and choice, not on whether it can hand-assemble calldata.
On a shell, cd ~/my/path && ls -al is parsed into syscalls the kernel runs against the filesystem; you never write the syscall yourself. Onchain, the equivalent of a command is a call against a smart contract — USDC(0xA0b8…48).balanceOf(0xAlice…). Something must turn that human-readable statement into the bytes an Ethereum node accepts — a 4-byte selector plus 32-byte ABI-encoded arguments — and make the eth_call. In Aomi, that something is always the harness.

Figure 4 — The read/encode harness. On the read path, get_contract checks a local ABI/source cache, fetches on a miss, and resolves proxies (EIP-1967); view functions are auto-encoded, the eth_call is issued, and the raw 32-byte result is formatted before the model sees it (1291473 with decimals = 6 becomes "1.291473"). On the write path, the model emits high-level intent and the harness assembles the transaction. The amber panel is the point: the harness owns every byte; the model owns only addresses, signatures, and base-unit amounts.
Here is a real stage_tx argument for "Approve 500 USDC for the Uniswap router":
{
"to": "0xA0b86991c6218b36c1d19D4a2e9Eb0cE3606eB48", // ① USDC contract address
"description": "Approve 500 USDC for Uniswap V3 Router", // ② human-readable UI label
"data": {
"encode": {
"signature": "approve(address,uint256)", // ③ Solidity-style signature
"args": [
"0xE592427A0AEce92De3Edee1F18E0157C05861564", // ④ spender (the router)
"500000000" // ⑤ amount in base units (500 × 10^6)
]
}
},
"value": "0", // ⑥ native value in wei (none here)
"kind": "erc20_approve" // ⑦ semantic tag for safety hooks
}
Code 1. Everything ①–⑦ is human-readable; the model emits no selector and no 32-byte word. The harness computes keccak256("approve(address,uint256)")[:4] = 0x095ea7b3, ABI-encodes each argument, concatenates the calldata, injects from and chain_id from wallet context, and pushes the result to the pending queue. One nuance: unit conversion is asymmetric — the harness owns all encoding and all output formatting, but on the raw write path the model still supplies the amount in base units (it computed 500 × 10^6 itself). The skills layer can close even that gap for specific protocols.

Figure 5 — The handoff. Three steps across the two ground truths. The agent stages an action into UserState.pending_transactions (intent, reversible; checked by PendingTxs / PendingEip712s assertions). commit_txs → wallet_tx_request → SIGN mutates chain state on the fork (outcome, final; checked by BalanceDelta / EventLog assertions). A wallet:tx_complete callback reconciles and discards the pending ids from UserState (queue cleared, success or fail).
3. The benchmark: methodology, tasks, verification
3.1 What a task is
An AomiBench task consists of (1) a user-story instruction in natural language; (2) a chain environment — a pinned fork block, wallet state, and account set; (3) a scoped tool surface — the typed tool catalog and skills made visible for the task; (4) a deterministic specification — required and warning assertions over observable evidence; and (5) a reference solution — a tool path known to satisfy the specification. A run (or trial) is one live agent session — one model, one task, one tool surface, one chain environment, one wallet state, one or more user turns — and the harness records the full trajectory (transcript, tool calls, wallet events, callbacks, state mutations, balances, logs, timing, tokens, assertion results) as replayable JSON.
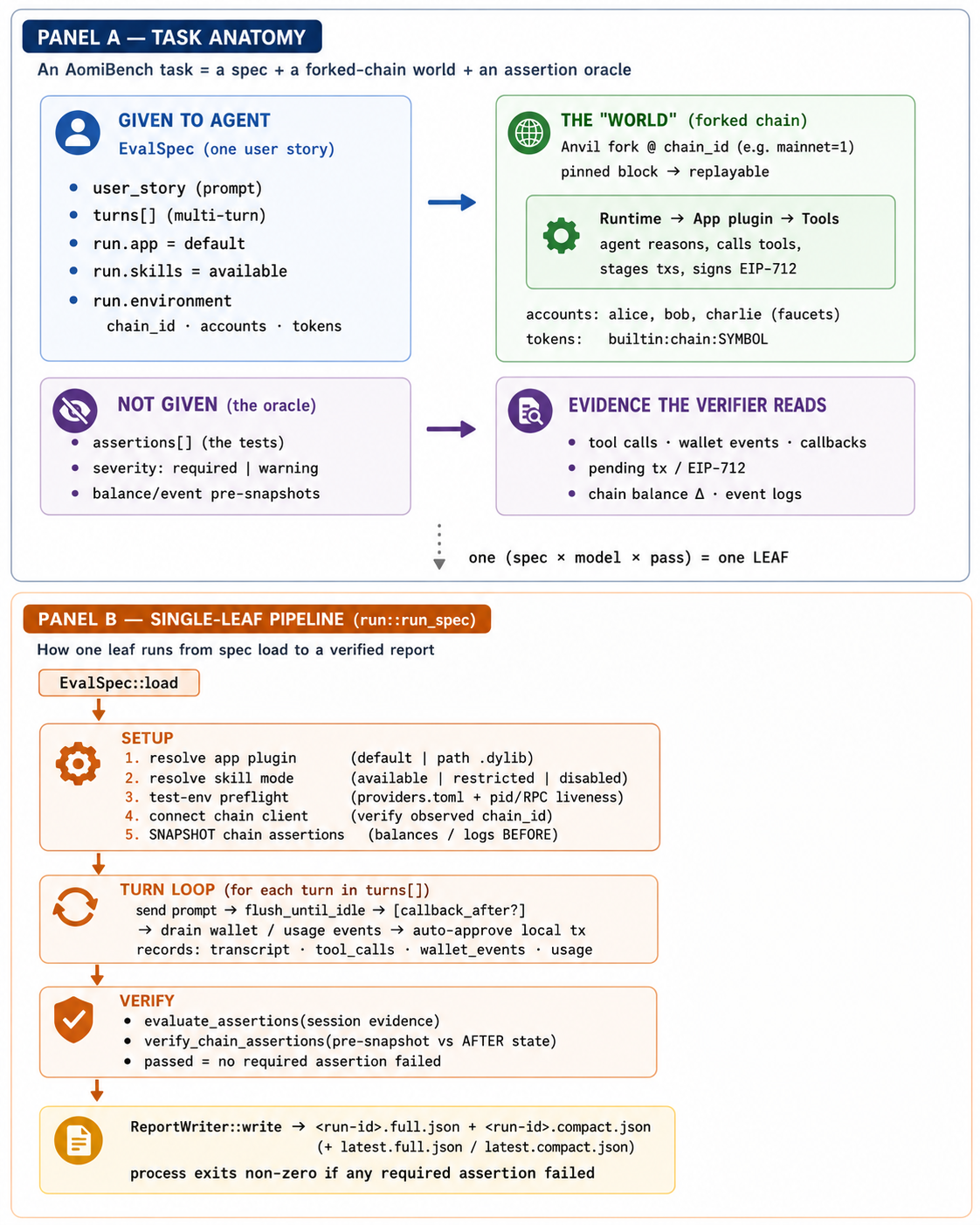
Figure 6 — Task anatomy and the single-leaf pipeline. Panel A: a task is a spec plus a forked-chain world plus an assertion oracle. The agent is given an EvalSpec (one user story, its turns, and a run environment) and acts in a world that is an Anvil fork pinned at a block; it is not given the assertions, which the verifier evaluates against observed evidence (tool calls, wallet events, callbacks, pending tx / EIP-712, chain balance deltas, and event logs). One (spec × model × pass) is one leaf. Panel B: how a single leaf runs, from EvalSpec::load through setup (resolve the app plugin and skill mode, preflight the test environment, connect the chain client, snapshot balances and logs BEFORE), the turn loop (send prompt, flush to idle, drain wallet and usage events, auto-approve the local tx), verification (evaluate session and chain assertions against the before-snapshot), and ReportWriter::write. The process exits non-zero if any required assertion failed.
3.2 When a task is valid
A task is considered verified when it meets four criteria, checked against its reference solution and recorded trajectory:
- Specificity. The required assertions pass if and only if the run's observable evidence corresponds to an acceptable end-state.
- Solvability. A reference solution exists and, when executed in CI, satisfies every required assertion.
- Integrity. The agent cannot pass by shortcut — it cannot fabricate pending-transaction IDs, self-approve, skip authorization, or otherwise produce evidence without the underlying action.
- Safety. For review-first and read-only tasks, the spec asserts the absence of unsafe side effects, so an agent that "succeeds" by overstepping fails.
Two automated checks back these continuously: the reference-solution CI run (solvability) and the skill-doctor job that re-checks each skill's addresses and parameters against the live chain so a task's protocol facts do not drift.
3.3 How we built the suite
AomiBench v0.1 comprises 50 tasks across 7 families: 26 specs from the original public suite plus a 2026-05-31 expansion of 25, of which 24 were included. The remaining expansion spec, send_base_usdc_to_bob, was quarantined because every attempt failed before staging once the agent observed that the test account held 0 Base USDC — a fixture-funding problem in the task, not a model failure. Each task is written as a user story — something a wallet user might plausibly want — not as a list of harness instructions, so the agent must choose the route through the runtime itself.
3.4 What we verify
The verifier is deterministic and assertion-based: a spec declares the externally observable facts that must hold, and the harness checks them against the recorded trajectory and chain state.

Figure 7 — Assertion & verification taxonomy. Verification draws on three evidence kinds — deterministic simulation (predicted state, traces, gas, events, before authorization), pinned-fork replay (end-state equivalence after the action), and wallet/callback evidence (the authorization round-trip and wallet:tx_complete). Required assertions gate pass/fail; warning assertions add diagnostic signal. Two principles sit underneath: execution correctness is not economic correctness (assert the objective — route, amount, resulting state — not just that a tx landed), and safety is part of correctness (review-first tasks assert the absence of unsafe side effects).
A concrete example. One task is written simply as:
Swap 0.05 ETH from Alice for USDC using Uniswap V3 on Ethereum.
The model is never told which internal tools to call. That one sentence implies an execution contract, and the required evidence makes it explicit:
tools: activate_skills -> get_time_and_onchain_context -> encode_and_call
-> stage_tx -> simulate_batch -> commit_txs
stage_tx.to = 0x68b3465833fb72A70ecDF485E0e4C7bD8665Fc45 # Uniswap V3 router (SwapRouter02)
stage_tx.value = 50000000000000000 # 0.05 ETH in wei
callback: wallet:tx_complete, status = success
balance_delta: Alice ETH ~= -0.05 ± 0.01
event_log: USDC Transfer(address,address,uint256), min_count = 1
Code 2. The run is credited only when the harness observes that path and that evidence — the right tool sequence, the right router target and value, a successful wallet callback, the ETH balance moving, and a USDC Transfer log appearing.
Most tasks are not that simple. Here is a harder one on Aerodrome (a decentralized exchange on Base), where the agent has to split an amount, sequence three dependent transactions, and commit them as a single batch:
Use 1 ETH total from Alice to add equal-weight liquidity to the Aerodrome ETH/USDC pool on Base.
Swap half of the ETH to USDC first, then add both sides as liquidity.
The required evidence:
tools: activate_skills -> get_time_and_onchain_context -> get_account_info
-> encode_and_call (pool lookup, decimals, quotes)
-> stage_tx (swap) -> stage_tx (approve) -> stage_tx (add-LP)
-> simulate_batch -> commit_txs # tx_ids [1, 2, 3]
stage_tx[0].to = 0xcF77a3Ba9A5CA399B7c97c74d54e5b1Beb874E43 # Aerodrome Router: swap 0.5 ETH -> USDC
stage_tx[0].value = 500000000000000000 # 0.5 ETH in wei
stage_tx[1].to = 0x833589fCD6eDb6E08f4c7C32D4f71b54bdA02913 # USDC (Base): approve router to spend USDC
stage_tx[1].value = 0
stage_tx[2].to = 0xcF77a3Ba9A5CA399B7c97c74d54e5b1Beb874E43 # Aerodrome Router: addLiquidity (0.5 ETH + USDC)
stage_tx[2].value = 500000000000000000 # the other 0.5 ETH in wei
callback: wallet:tx_complete, status = success
balance_delta: Alice ETH ~= -1 ± 0.15 # 0.5 swapped + 0.5 into the LP
event_log: Base USDC moved (swap-out + LP-in), min_count = 2
event_log: WETH moved into the Aerodrome LP, min_count = 1
event_log: Aerodrome WETH/USDC LP token minted, min_count = 1
Code 3. This is a real step up from the swap. The agent has to split the amount (1 ETH into 0.5 to swap and 0.5 into the LP) and size the USDC side from a live quote it reads itself; order three dependent actions (swap to obtain USDC, approve the router to spend it, then add liquidity) and commit them as one batch; route correctly, using the Aerodrome Router for the swap and the LP but the USDC contract for the approve; and leave four pieces of evidence, including a min_count of 2 on USDC transfers and the LP-token mint. None of the addresses, the split, or the ordering appears in the instruction.
3.5 The task families
The spread tests whether a model can preserve intent across different shapes of onchain action — read, quote, stage, simulate, authorize, wait, or stop safely — rather than topping a single-protocol leaderboard.
Table 3 — Task families. Task success rate is the per-family pass rate across all models and passes.
| Task family | Tasks | Task success rate | Example scenarios | What it measures |
|---|---|---|---|---|
| Wallet state & read-only checks | 15 | 0.98 | Check Base ETH, Base USDC, ZORA balance, market/credit state | Reads the right state without staging unsafe actions |
| Transfers & signatures | 4 | 0.84 | Send ETH or USDC; request a harmless EIP-712 login signature | Distinguishes transfers from signatures; right wallet event; no extra pending txs |
| Swaps & quotes | 5 | 0.91 | Swap ETH→USDC via Uniswap, SushiSwap, Curve, Aerodrome; CoW / 1inch quotes | Selects the route, stages valid calldata, simulates before authorizing |
| Lending & borrowing | 6 | 0.91 | Supply USDC to Aave or Compound; deposit ETH collateral and borrow USDC | Approval + protocol-action ordering, balance deltas, logs, callbacks |
| Staking & restaking | 12 | 0.82 | Lido, Rocket Pool, ether.fi, Kelp, Renzo, Mantle mETH, Yearn | Protocol-specific skills/guards, right contracts, received assets |
| Liquidity provision | 3 | 0.81 | Swap half, then add both sides as LP on Aerodrome or Uniswap V2 | Multi-step sequencing, amount splitting, resulting LP evidence |
| Bridging & review-first | 5 | 0.99 | Base native bridge, CCTP, Optimism, zkSync, Across route lookup | Recipient/refund intent, chain context, pauses when asked to review |
3.6 Experimental setup
We ran AomiBench v0.1 across 50 specs, 2 passes per model, on 7 public models — 700 expected runs, of which 694 produced scorable JSON (6 emitted none and are excluded from JSON-only rates). Every model ran through the same fixed scaffold: identical prompt profile, tool surface, skill system, protocol guards, wallet state, fork state, and budgets. Only the model changed. This is an apples-to-apples model comparison, in the spirit of Terminal-Bench's neutral Terminus 2 scaffold and SWE-bench Verified's bash-only mode — and it means the scores are the joint product of model and harness, not a measure of model intelligence in isolation. The primary metric is task success rate, the fraction of runs that pass all required assertions (single attempt — no best-of-k retries). The secondary Aomi score is a partial-credit companion: the mean fraction of required assertions passed per run, ×100.
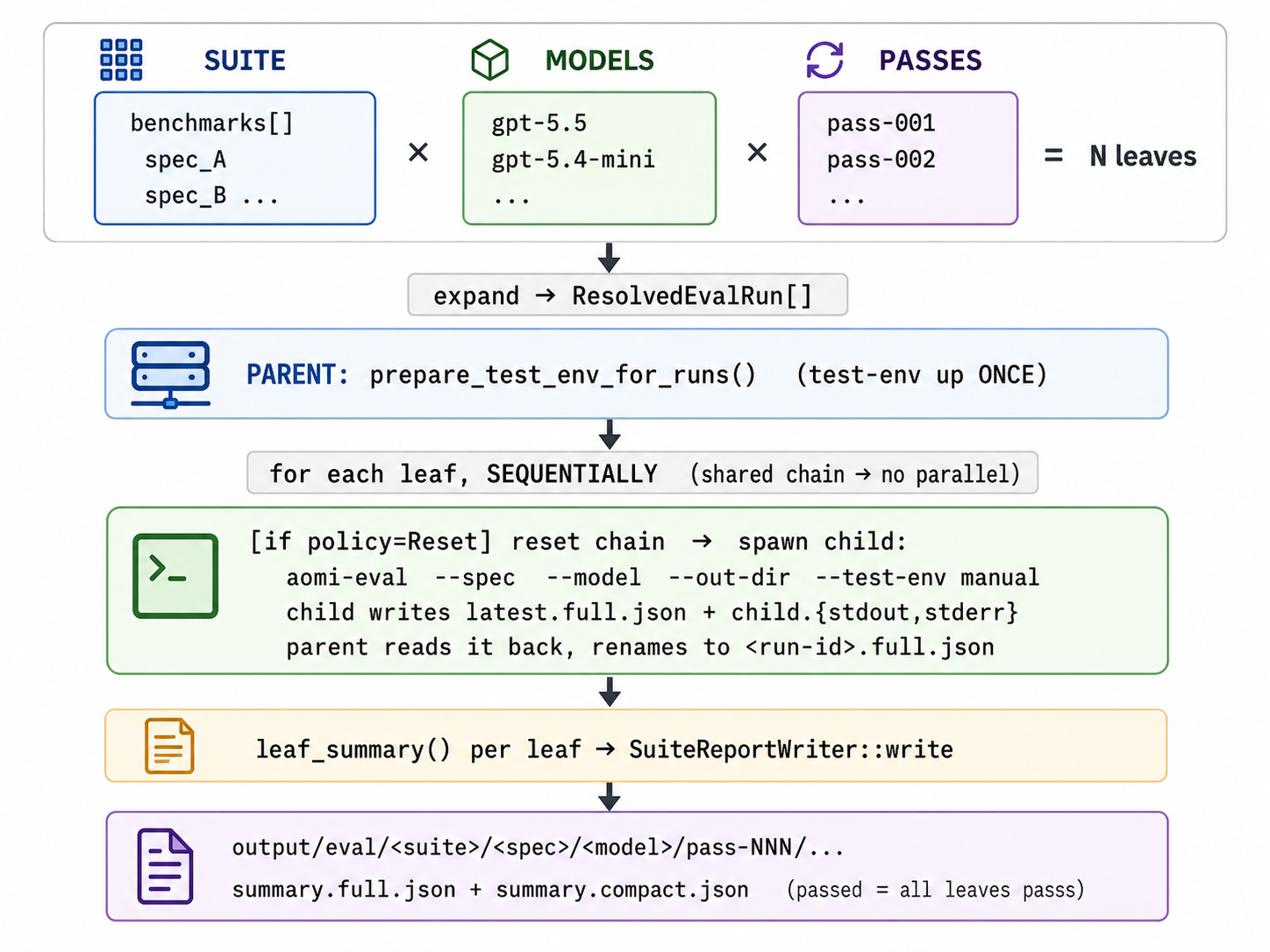
Figure 8 — The eval matrix and the run loop. A suite expands to N leaves: benchmarks[] (specs) × models × passes → ResolvedEvalRun[]. The parent brings the test environment up once, then runs each leaf sequentially — the shared chain rules out parallelism. On a Reset policy it resets the chain and spawns a child process (aomi-eval --spec --model --out-dir --test-env manual) that writes latest.full.json, which the parent reads back and renames to <run-id>.full.json. A per-leaf leaf_summary() feeds SuiteReportWriter, which writes the suite outputs under output/eval/<suite>/<spec>/<model>/pass-NNN/ as summary.full.json and summary.compact.json; a spec passes only when all of its leaves pass.
4. Discussion: the harness mechanisms, and what they reveal
Three mechanisms make high-stakes, irreversible actions tractable to benchmark — and the runs exposed distinct failure modes worth designing against.
4.1 Skills: scoped runtime profiles
A frozen base model knows canonical assets (USDC, WETH), standard ERC-20 patterns, and the shape of a vanilla swap — effectively in the weights. Bespoke pools, niche protocols, meme coins, and anything deployed after a model's cutoff are not, and no cleverness recovers an address or ABI the model never saw. A skill patches that gap, and it does so on three axes at once, all skill-scoped (present only while active, off by default).

Figure 9 — A skill delivers three things. Knowledge (protocol addresses, ABI signatures, procedure) tells the model what to call; capability (purpose-built encoders) gives it a verb it lacked; safety (guards) bounds what can go wrong. Critically, skill-scoping is also what defines each task's action space: capability is granted protocol-by-protocol, not preloaded into every prompt. Skills are compiled from a JSON manifest plus a markdown template, and a skill-doctor job re-checks each skill against the live chain so addresses and parameters do not rot.
4.2 Guards: a hard gate before authorization
Guards are wired as post_call hooks: a dispatch runs pre_call hooks, then the tool, then post_call hooks that can inspect and overwrite the tool's return. Because simulate_batch is itself a tool, the guard inspects the simulation result before it reaches the model or the wallet. If a guard returns Block(reason), the harness replaces the return with an error and the transaction is never staged. The model cannot bypass it — a hard gate on the path to authorization, not advice.

Figure 10 — The post-simulation gate. The 27 registered guards (configured from each skill's manifest) check the target against an allowlist, the approve spender against an approved set, selectors under default-deny, sentinel/burn recipients paired with a missing sweep, recipient/owner identity, parameter sanity, and slippage bounds. Because they run against the simulated outcome, they catch malformed or value-losing actions at the last safe moment — after the dry run, before any signature. This is the contrast with a coding benchmark like Terminal-Bench: their agent gets a full shell (maximum generality, and a correspondingly large surface for mistakes); Aomi's gets a curated, guarded, per-skill capability surface. That curation is "guarded generality," and it is what makes irreversible onchain actions safe to benchmark.
4.3 Injected tools: bounded capability, not a shell
The capability axis is delivered by purpose-built encoders, not a general execute. Some actions — a multicall(bytes[]), Uniswap V4 packed actions, Solana instructions — cannot reasonably be hand-assembled by a model emitting strings. They require constructing nested, offset-encoded byte structures: a dynamic bytes[] array carries an internal layout of offset pointers and per-element lengths, each element is itself a fully ABI-encoded inner call, and the whole thing is prefixed by a function selector the model would have to compute as keccak256(signature)[:4]. Asking a language model to lay those bytes out by hand is asking it to guess — and onchain, a wrong offset doesn't throw a friendly parse error, it executes as some other transaction.
So instead of exposing that surface, a skill injects a tool that owns the encoding. For Uniswap, encode_and_simulate_multicall accepts the swap as a list of high-level steps — each a function signature plus its arguments — and the harness assembles the inner calls, packs them into the multicall(bytes[]) envelope, attaches the deadline, and simulates the result. The model expresses what it wants (an exactInputSingle followed by a sweepToken); the harness produces the bytes. The same pattern covers Uniswap V4's packed action codes and Solana's instruction serialization — each a venue-specific encoding the standard ABI path cannot express, each turned into a small, declarative tool.

Figure 11 — Bounded capability, not a shell. Without an injected tool the model would hand-assemble the multicall bytes; with encode_and_simulate_multicall it emits high-level steps and the harness produces, wraps, and simulates the calldata, then runs guard checks. The model never sees the bytes.
Crucially, these tools are skill-scoped. An injected tool is owned by exactly one skill and is invisible — and uncallable — until that skill is active. The harness enforces this at dispatch: gate_injected_tool rejects any call to a tool whose owning skill has not been activated, returning a skill_not_active error rather than executing it. Activating a skill therefore does something narrower and safer than handing the model a shell: it turns on one specific runtime capability and turns it off again when the skill deactivates. The action space grows by exactly one well-understood verb, not by an open-ended interpreter.
This is a deliberate design stance. We could give an onchain agent a general-purpose execution primitive and let it improvise; we chose many narrow, guarded encoders instead. Each injected tool has a known shape, a known protocol, and (Section 4.2) a guard that inspects its simulated effect before anything is signed. Capability is granted per-protocol, on demand, and revocably — which is what makes it tractable to reason about what an agent can do at any given moment, a question that has no bounded answer when the primitive is bash.
One honest caveat: the agent is not hermetically sandboxed to these named verbs. A raw-calldata path still exists — stage_tx accepts pre-built data.raw, and a generic encoder will encode any signature — so the true bound on generality comes from the guards in Section 4.2, not from the absence of a raw path. The honest framing is "guarded generality," not "no generality."
4.4 What the runs revealed about model behavior
Three patterns stand out.
Safety pauses scored as failures. Of the 65 strict JSON-scored failures, 9 were not capability failures: on a 10 ETH transfer (transfer_eth_to_charlie), several models staged the transaction, observed a passing simulation, then paused for confirmation because the amount tripped a $5,000 safety threshold — the desired behavior — but strict scoring failed them for not reaching commit_txs. Crediting those nine raises the rate to 91.9%. We keep the deterministic verifier as the headline and treat this as a verifier-design fix for v0.2: review-first tasks should assert the pause, not the commit. It is why transfer_eth_to_charlie is the single hardest spec in the suite, at a 50% pass rate.
A knowledge gap even top models hit. Here is one real failing run:
Task: check_zora_token_balance — "Check Alice's ZORA token balance on Base?" (read-only)
Model: gpt-5.5 (a top scorer overall)
What it did: activated the zora skill but never issued a well-formed encode_and_call
First bad step: sequence broke before encode_and_call — no matching `to` (ZORA contract),
no matching `function_signature` (balanceOf(address))
Failed check: tool assertion (required → run fails); both passes failed identically
Code 4. The task is conceptually trivial — read one ERC-20 balance — and the model is otherwise strong. ZORA is a newer Base token whose address and ABI are not reliably in-weights, so without grounding on the skill's contract data the agent could not form the read. It is the same long-tail gap the skills layer exists to close, surfacing even on a read-only task.
Recurring failure signatures and the difficulty split. Across the run, strict failures clustered into two signatures: tool-sequence or argument mismatches (wrong or missing to/value/signature, or breaking before stage_tx/commit_txs), and missing post-execution evidence (no wallet:tx_complete callback, a zero balance delta, or an absent Transfer log) — often co-occurring on a single run. Of the 50 specs, 28 were solved by every model on both passes, 22 separated the field, and none went unsolved. A structured, blockchain-specific error taxonomy (wrong chain/address, approval sequencing, slippage/amount math, nonce/fee/timeout, bridge finality, unsafe-action attempts, verifier mismatches) lands in v0.2, each tagged with the first bad step and the exact failed check.
5. Results
5.1 Headline: task success rate across models
Figure 1 (above) gives the headline; the full per-model picture follows. Overall, models passed 629 of 694 scorable runs (90.6%). The top five clustered at 94.8–99.0% task success rate; minimax-m2.5 (76.8%) and haiku-4.5 (74.0%) trailed. Of the 50 specs, 28 were solved by every model on both passes and 22 separated the field — the saturation that motivates a harder v0.2. (Headline caveat: 9 of the 65 failures were correct safety pauses; see Section 4.4.)
Table 4 — Per-model results.
| Model | Task success rate | Aomi score | Median cost (cr) | Median latency | Output tok/test |
|---|---|---|---|---|---|
opus-4.6 | 99.0% | 99.0 | 5.78 | 32.5s | 1,094 |
opus-4.8 | 98.0% | 98.0 | 5.33 | 45.2s | 553 |
sonnet-4.6 | 96.0% | 96.8 | 4.39 | 42.2s | 1,814 |
gpt-5.5 | 96.0% | 97.8 | 6.86 | 25.0s | 868 |
opus-4.7 | 94.8% | 96.0 | 5.01 | 31.1s | 496 |
minimax-m2.5 | 76.8% | 86.1 | 1.17 | 31.4s | 373 |
haiku-4.5 | 74.0% | 84.5 | 1.36 | 25.5s | 1,767 |
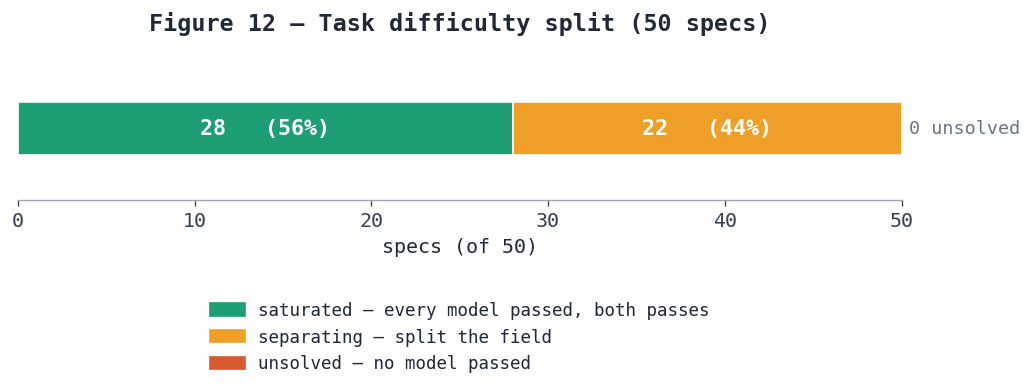
Figure 12 — Task difficulty split. Of the 50 specs, 28 (56%) were saturated — solved by every model on both passes — 22 (44%) separated the field, and none were unsolved. The separating tasks are where v0.2 lives.
5.2 Where models diverge: by family
By family, task success rate ran from 0.98–0.99 on read-only and bridging/review-first tasks down to 0.81–0.84 on the multi-step families — transfers-and-signatures (0.84, depressed by the safety-pause artifact in Section 4.4), staking/restaking (0.82), and liquidity provision (0.81) — where approval ordering, amount splitting, and sequencing create more ways to break.
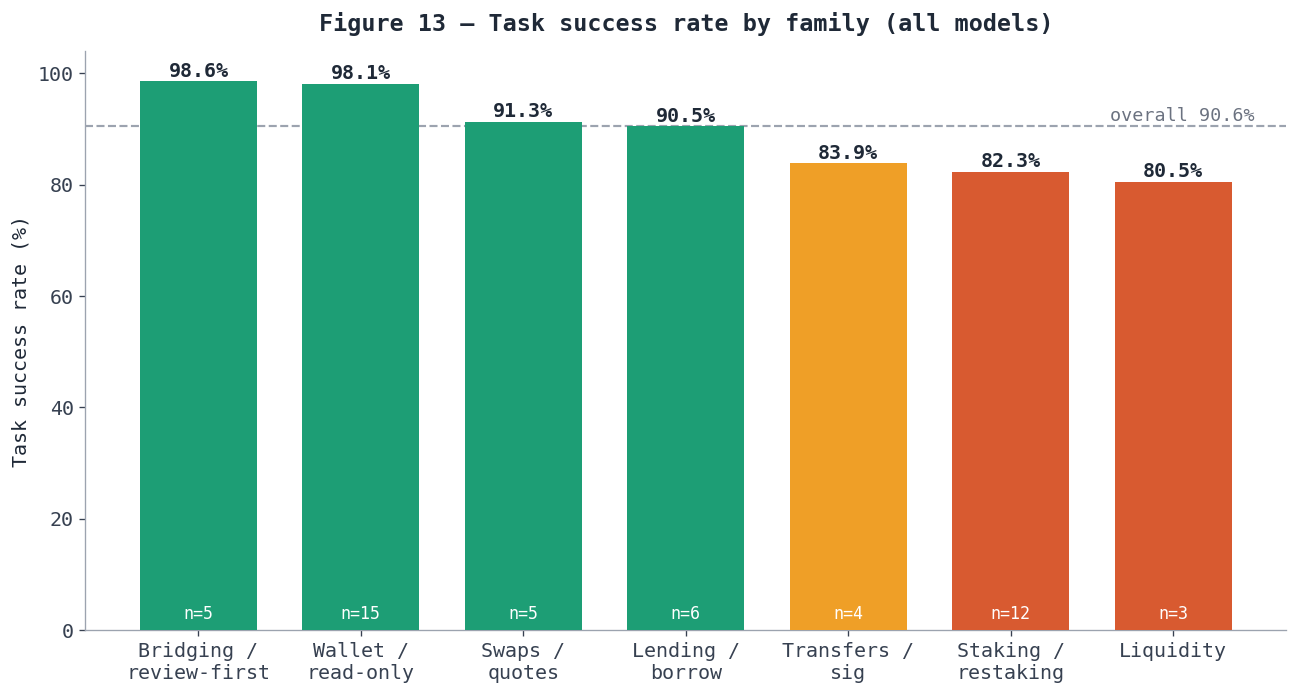
Figure 13 — Task success rate by family. Read-only and bridging/review-first tasks sit at or above the 90.6% overall line; the multi-step families (transfers, staking, liquidity) fall to the low 80s. Bar labels show family size (n).
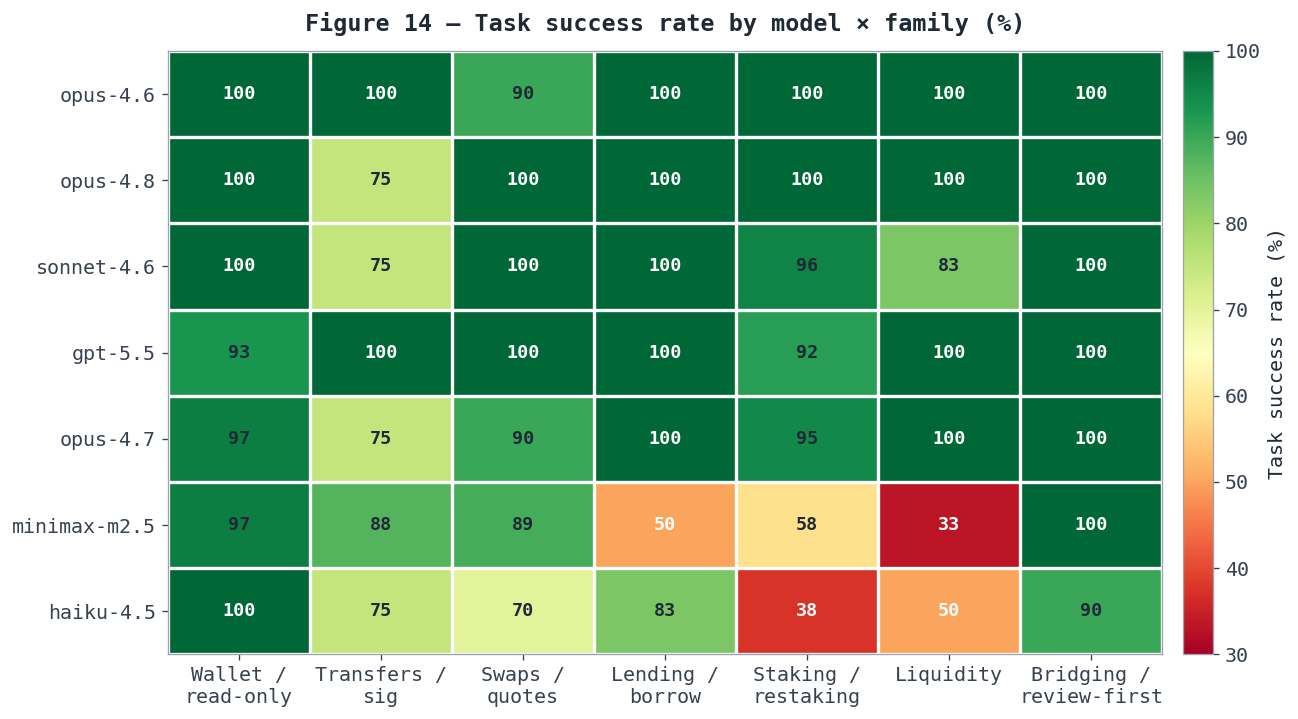
Figure 14 — Task success rate by model × family. The frontier models are near-uniform green; the gap opens on the smaller models in the multi-step families, where minimax-m2.5 and haiku-4.5 drop into the 30s–50s on lending, staking, and liquidity.
5.3 Cost, latency, and efficiency
Correctness is one dimension; cost and latency decide deployability. gpt-5.5 was the fastest top-tier model (25s median) but also the most expensive (≈6.9 credits/task median, the highest in the set), while minimax-m2.5 and haiku-4.5 were cheapest (≈1.2 and 1.4 credits) but lowest-scoring. The most favorable profile in v0.1 was opus-4.8: 98.0% task success rate at ~5.3 credits and ~553 output tokens per task. Output-token usage varied nearly 5×, from 373 (minimax-m2.5) to 1,814 (sonnet-4.6), and efficiency did not track accuracy — opus-4.8 reached 98.0% on roughly 0.3× the tokens sonnet-4.6 spent for a lower 96.0%. Latency ranged from a 25s median up to a single 421s run; slow runs often came from tool misuse or repeated attempts, which matters for wallet UX.
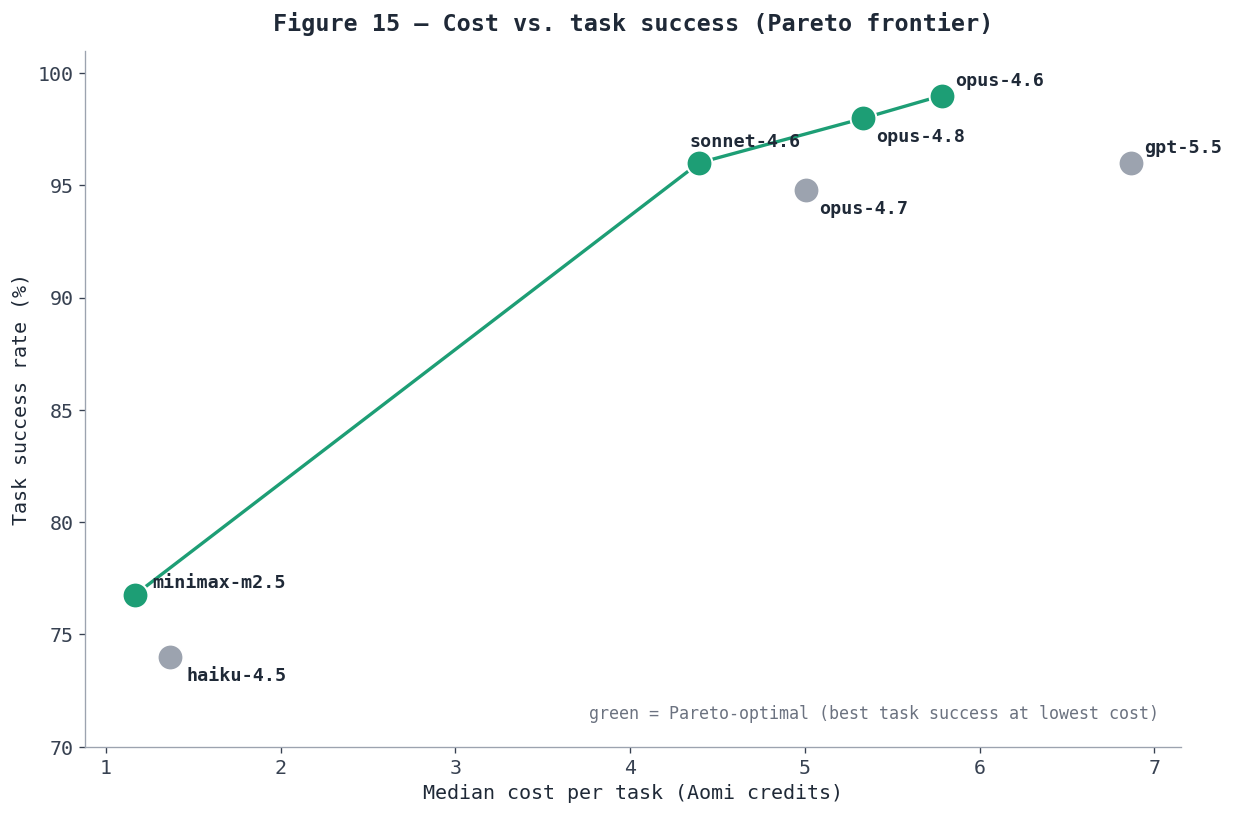
Figure 15 — Cost vs. task success. The green Pareto frontier (minimax-m2.5, sonnet-4.6, opus-4.8, opus-4.6) gives the best task success at a given cost; opus-4.7, haiku-4.5, and gpt-5.5 are dominated. gpt-5.5 is the most expensive model despite not topping the frontier.
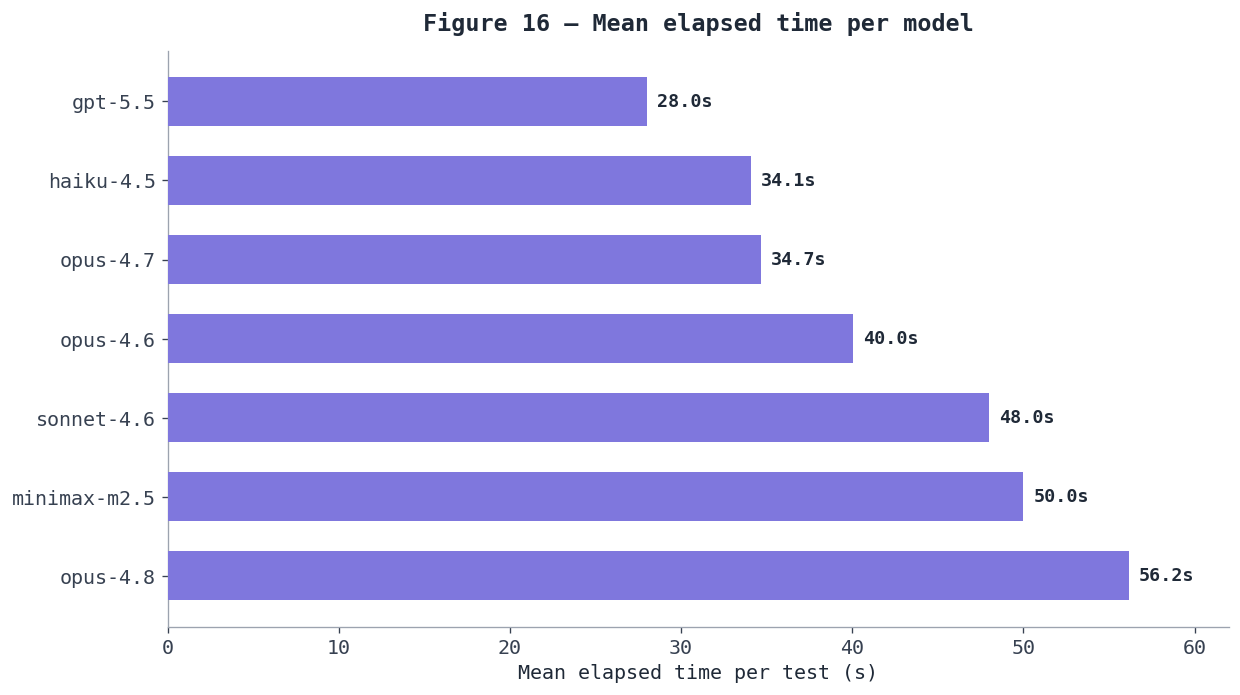
Figure 16 — Mean elapsed time per model. From 28s (gpt-5.5) to 56s (opus-4.8) per test on average; slower runs often came from tool misuse or repeated attempts, which matters for wallet UX.
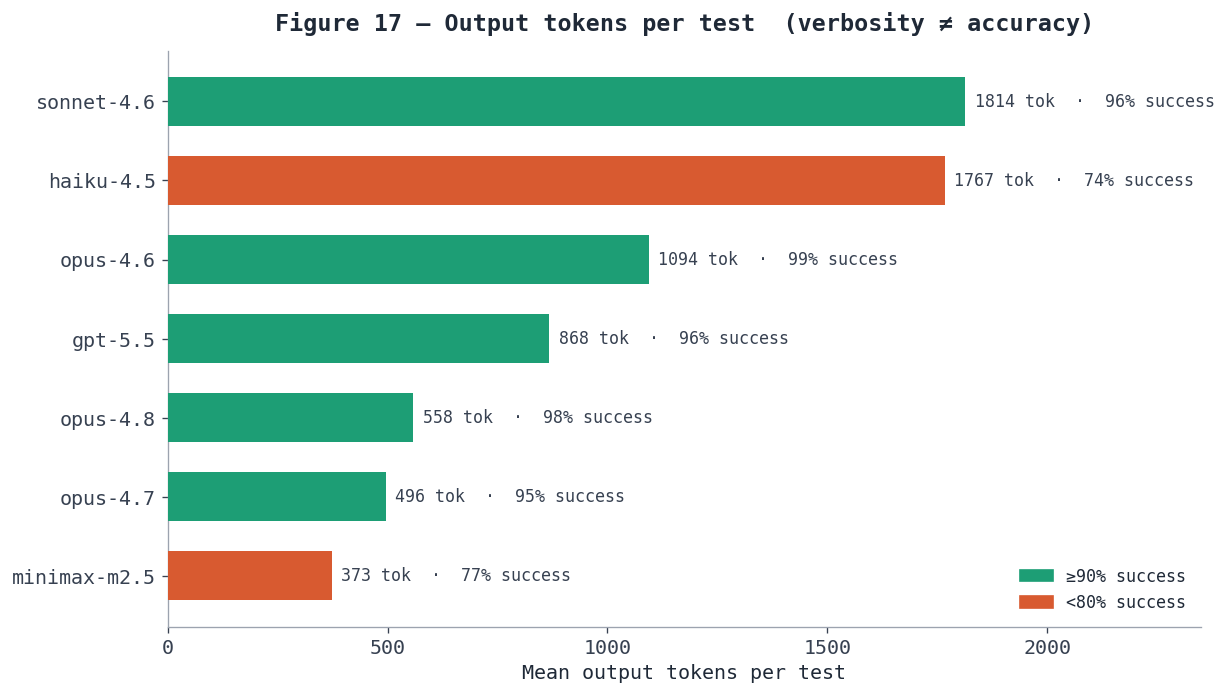
Figure 17 — Output tokens per test. Token spend does not track accuracy: sonnet-4.6 spends the most (1,814) for 96%, while opus-4.8 reaches 98% on 558 and opus-4.7 95% on 496; minimax-m2.5 is leanest (373) but lowest-scoring (77%).
6. Harness card
In agentic benchmarks the configuration is part of the result, especially when comparing models inside a shared scaffold.
Table 5 — Harness card.
| Field | Value |
|---|---|
| Benchmark / split | aomi-bench-v0.1 (public-skills suite, 50 specs) |
| Build | git 5b026609 (working tree dirty) |
| Models | opus-4.6, opus-4.8, opus-4.7, sonnet-4.6, gpt-5.5, minimax-m2.5, haiku-4.5 |
| Verifier | deterministic, assertion-based on recorded trajectory + chain state |
| Toolset | activate_skills, get_time_and_onchain_context, get_account_info, get_contract, encode_and_call, stage_tx, simulate_batch, commit_txs (+ per-skill injected encoders) |
| Skills | public-skills set; skill-scoped (off by default) |
| Wallet / accounts | funded local test accounts (Alice primary; Bob, Charlie as recipients) |
| Chains | Ethereum (1) and Base (8453); bridge tasks target Optimism and zkSync |
| Test environment | local fork, reset between tests; wallet requests auto-approved by impersonating the pending sender and feeding a wallet:tx_complete callback |
| Turn timeout | {{HC_TURN_TIMEOUT}} (not in dataset — confirm) |
| Passes per spec | 2 |
7. Related work
AomiBench sits in the execution-benchmark tradition. SWE-bench grades whether a generated patch resolves a real GitHub issue under tests; SWE-bench Verified adds human-validated tasks and a fixed scaffold. Terminal-Bench evaluates agents on hard command-line tasks, checking final container state rather than the command sequence, and uses a neutral scaffold (Terminus 2) to separate model from agent. WebArena and its verified variants evaluate web agents against backend-state checks. Tool-use and function-calling benchmarks (τ-bench, the Berkeley Function Calling Leaderboard) measure structured tool invocation, and computer-use suites (OSWorld, AppWorld) measure control of realistic software environments. AomiBench is distinguished by its domain: a stateful, financially sensitive, irreversible environment where the source of truth is the chain itself, and where safety — not just task completion — is part of the verifier.
8. Limitations
AomiBench v0.1 is an early, controlled benchmark, not a universal measure of model quality.
- It runs in a controlled environment (local forks, auto-approved wallet callbacks). This improves repeatability but does not fully capture live production conditions.
- Each model/spec pair ran 2 times — enough for an early stability signal, not for confidence intervals or strong statistical claims. (Terminal-Bench, by comparison, ran ≥5 passes per model-agent pair.)
- One expansion spec (
send_base_usdc_to_bob) was quarantined for a fixture-funding fault, and 6 of 700 runs produced no scorable JSON; both are excluded from the JSON-only rates. - The task set is broad but incomplete — it does not yet fully cover all chains, wallets, multisigs, account-abstraction flows, bridge-finality cases, adversarial protocols, or live market drift.
- The scores are harness-specific and reflect model and scaffold jointly; they should not be read as a general ranking of model intelligence.
- The suite, full harness, and raw traces are not yet released as a public package.
Read the task-success-rate numbers as product-and-harness signal — task completion backed by observable wallet, tool, callback, and chain-state evidence — not as a leaderboard of raw capability.
9. What's next
The roadmap runs along two lines: harder tasks with deeper evaluation, and opening the harness up so anyone can use it.
- Harder task splits: cross-chain and cross-protocol execution, and long-horizon intent that spans many dependent steps, built to separate frontier models where v0.1 saturates.
- Wider model coverage at both ends of the range. A core goal of Aomi is a harness usable enough that even small, low-cost models can transact reliably through it, so we benchmark the low end as deliberately as the high end.
- Deeper evaluation: more passes per spec for variance and confidence intervals, plus behavioral telemetry such as tool-call patterns, tool-call frequency, and tool calls per task.
- Aomi as a remote runtime: the same tools, skills, and guards shown here, exposed through product-owned APIs so agents can read chain state, stage, simulate, and request signatures through the same interface we benchmark.
- Self-serve benchmarking: with the harness reachable from local developer tooling, anyone can run their own model or agent against the suite and score it on the same verifier.
The standard we hold ourselves to is the one credible execution benchmarks converge on: publish the task, the verifier, the harness, the artifacts, and the failure cases.
10. Closing
The next generation of agents will not just retrieve information or produce text. They will hold wallet context, call tools, prepare transactions, request signatures, and act on stateful systems. That changes what evaluation has to measure: not the plausibility of a plan, but the actions an agent takes, the evidence it leaves behind, and the safety boundaries it keeps. AomiBench is a first step toward measuring that in the environment where it matters. The direction is settled: onchain agents should be judged by what they do onchain.